
- AwesomeHive Team
- 0 Comments
- 2511 Views
Data is a crucial asset for businesses of all sizes. Unsurprisingly, choosing the right data processing architecture is a top priority for many organizations. Two popular options for data processing architectures are Lambda and Kappa.
In this Guide, we’ll dive deeply into the key features and characteristics of these architectures and provide a comparison to help you decide which one is the best fit for your business needs. Whether you’re a data scientist, engineer, or business owner, this guide will provide valuable insights into the pros and cons of each architecture and help you make an informed decision on which one to choose.
Data Processing Architectures
Data processing architectures are systems designed to efficiently handle the ingestion, processing, and storage of large amounts of data. These architectures play a crucial role in modern businesses. They allow organizations to analyze and extract valuable insights from their data, which can be used to improve decision-making, optimize operations, and drive growth.
There are several different types of data processing architectures, each with its own set of characteristics and capabilities. Some famous examples include Lambda and Kappa architectures, which are designed to handle different types of data processing workloads like batch processing or real-time data processing and have their own unique strengths and weaknesses. It’s essential for businesses to carefully consider their specific data processing needs and choose an architecture that aligns with their goals and requirements.
Kappa Architecture
Key Features and Characteristics of Kappa Architecture
Kappa architecture is a data processing architecture that is designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data in real time. It was developed as an alternative to Lambda architecture, which, as mentioned above, uses two separate data processing systems to handle different types of data processing workloads.
In contrast to Lambda, Kappa architecture uses a single data processing system to handle both batch processing and stream processing workloads, as it treats everything as streams. This allows it to provide a more streamlined and simplified data processing pipeline while still providing fast and reliable access to query results.
Speed Layer (Stream Layer)
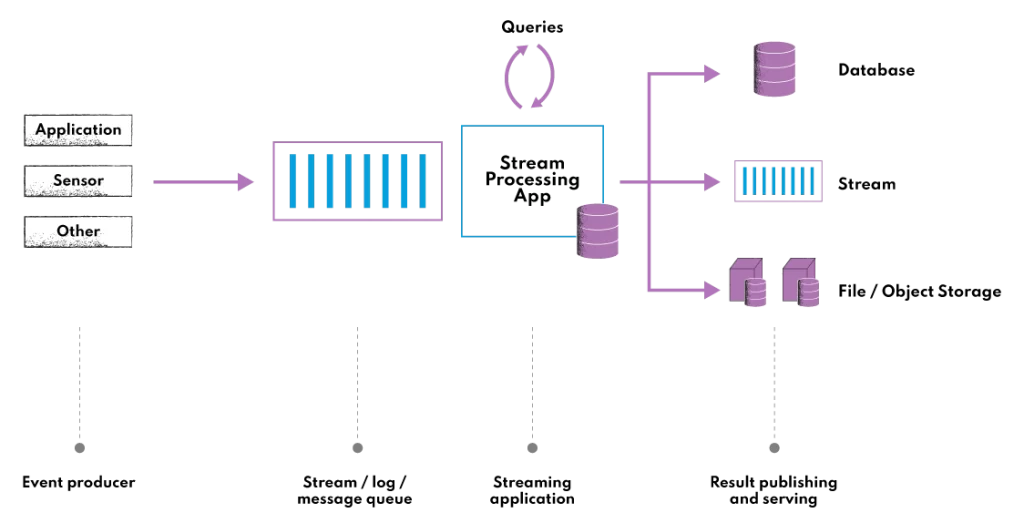
In Kappa architecture, there is only one main layer: the stream processing layer. This layer is responsible for collecting, processing, and storing live streaming data. You can think of it as an evolution of the Lambda approach with the batch processing system removed. It is typically implemented using a stream processing engine, such as Apache Flink, Apache Storm, Apache Kinesis, Apache Kafka, (or many other stream processing frameworks) and is designed to handle high-volume data streams and provide fast and reliable access to query results.
The stream processing layer in Kappa architecture is divided into two main components: the ingestion component and the processing component.
- Ingestion component: This component is responsible for collecting incoming data and storing raw data from various sources, such as log files, sensors, and APIs. The data is typically ingested in real-time and stored in a distributed data store, such as a message queue or a NoSQL database.
- Processing component: This component is responsible for processing the data as it arrives and storing the results in a distributed data store. It is typically implemented using a stream processing engine, such as Apache Flink or Apache Storm, and is designed to handle high-volume data streams and provide fast and reliable access to query results. In Kappa architecture, there is no separate serving layer. Instead, the stream processing layer is responsible for serving query results to users in real time.
The stream processing platforms in Kappa architecture are designed to be fault-tolerant and scalable, with each component providing a specific function in the real time data processing pipeline.
Pros and Cons of Using Kappa Architecture
Here are some advantages of using of Kappa architecture:
- Simplicity and streamlined pipeline: Kappa architecture uses a single data processing system to handle both batch processing and stream processing workloads, which makes it simpler to set up and maintain compared to Lambda architecture. This can make it easier to manage and optimize the data processing pipeline by reducing the coding overhead.
- Enables high-throughput big data processing of historical data: Although it may feel that it is not designed for these set of problems, Kappa architecture can support these use cases with grace, enabling reprocessing directly from our stream processing job.
- Ease of migrations and reorganizations: As there is only stream processing pipeline, you can perform migrations and reorganizations with new data streams created from the canonical data store.
- Tiered storage: Tiered storage is a method of storing data in different storage tiers, based on the access patterns and performance requirements of the data. The idea behind tiered storage is to optimize storage costs and performance by storing different types of data on the most appropriate storage tier. In Kappa architecture, tiered storage is not a core concept. However, it is possible to use tiered storage in conjunction with Kappa architecture, as a way to optimize storage costs and performance. For example, businesses may choose to store historical data in a lower-cost fault tolerant distributed storage tier, such as object storage, while storing real-time data in a more performant storage tier, such as a distributed cache or a NoSQL database. Tiered storage Kappa architecture makes it a cost-efficient and elastic data processing technique without the need for a traditional data lake.
When it comes to disadvantages of Kappa architecture, we can mention the following aspects:
- Complexity: While Kappa architecture is simpler than Lambda, it can still be complex to set up and maintain, especially for businesses that are not familiar with stream processing frameworks (review common challenges in stream processing).
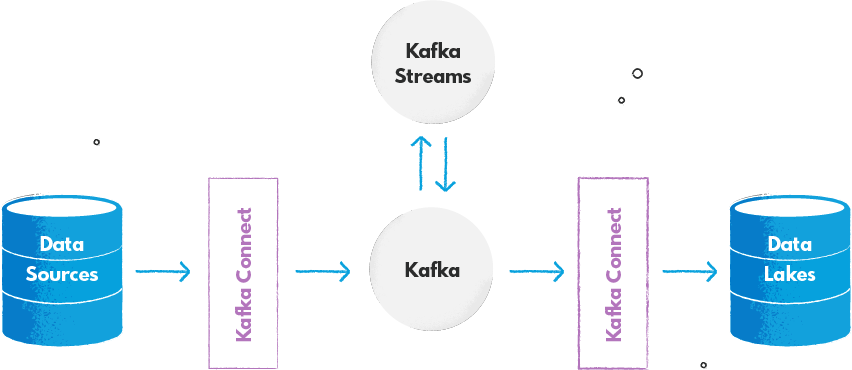
- Costly infrastructure with scalability issues (when not set properly): Storing big data in an event streaming platform can be costly. To make it more cost-efficient you may want to use data lake approach from your cloud provider (like AWS S3 or GCP Google Cloud Storage). Another common approach for big data architecture is building a “streaming data lake” with Apache Kafka as a streaming layer and object storage to enable long-term data storage.
Use Cases for Kappa Architecture
Kappa architecture is a data processing architecture that is designed to provide a flexible, fault-tolerant, and scalable architecture for processing large amounts of data in real-time. It is well-suited for a wide range of data processing workloads, including continuous data pipelines, real time data processing, machine learning models and real-time data analytics, IoT systems, and many other use cases with a single technology stack.
Lambda Architecture
Key Features and Characteristics of Lambda Architecture
Lambda architecture is a data processing architecture that aims to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data. It was developed by Nathan Marz in 2011 as a solution to the challenges of processing data in real time at scale.
The critical feature of Lambda architecture is that it uses two separate data processing systems to handle different types of data processing workloads. The first system is a batch processing system, which processes data in large batches and stores the results in a centralized data store, such as a data warehouse or a distributed file system. The second system is a stream processing system, which processes data in real-time as it arrives and stores the results in a distributed data store.
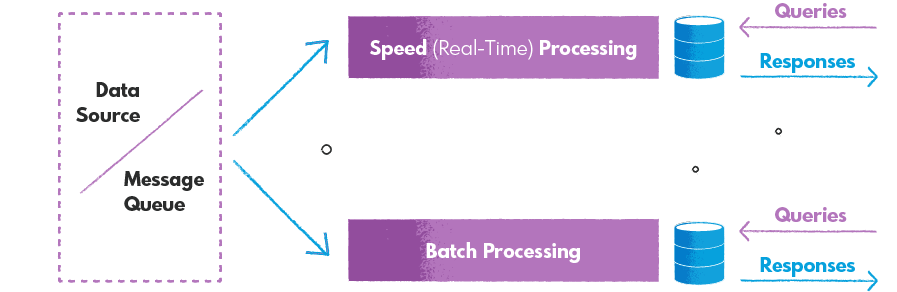
In Lambda architecture, the four main layers work together to process and store large volumes of data. Here’s a brief overview of how each layer functions:
Data Ingestion Layer
This layer collects and stores raw data from various sources, such as log files, sensors, message queues, and APIs. The data is typically ingested in real time and fed to the batch layer and speed layer simultaneously.
Batch Layer (Batch processing)
The batch processing layer is responsible for processing historical data in large batches and storing the results in a centralized data store, such as a data warehouse or a distributed file system. This layer typically uses a batch processing framework, such as Hadoop or Spark, to process the data. The batch layer is designed to handle large volumes of data and provide a complete view of all data.
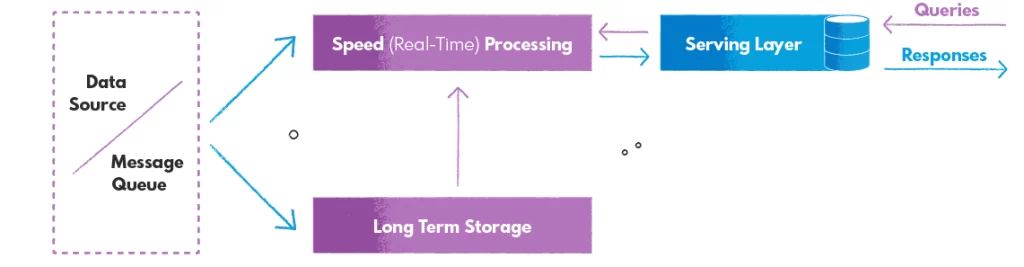
Speed Layer (Real-Time Data Processing)
The speed layer is responsible for processing real-time data as it arrives and storing the results in a distributed data store, such as a message queue or a NoSQL database. This layer typically uses a stream processing framework, such as Apache Flink or Apache Storm, to process data streams. The stream processing layer is designed to handle high-volume data streams and provide up-to-date views of the data.
Serving Layer
The serving layer is a component of Lambda architecture that is responsible for serving query results to users in real time. It is typically implemented as a layer on top of the batch and stream processing layers. It is accessed through a query layer, which allows users to query the data using a query language, such as SQL or HiveQL.
The serving layer is designed to provide fast and reliable access to query results, regardless of whether the data is being accessed from the batch or stream processing layers. It typically uses a distributed data store, such as a NoSQL database or a distributed cache, to store the query results and serve them to users in real time.
The serving layer is an essential component of Lambda architecture, as it allows users to access the data in a seamless and consistent manner, regardless of the underlying data processing architecture. It also plays a crucial role in supporting real-time applications, such as dashboards and analytics, which require fast access to up-to-date data.
Pros and Cons of Using Lambda Architecture
Here are some advantages of Lambda architecture:
- Scalability: Lambda architecture is designed to handle large volumes of data and scale horizontally to meet the needs of the business.
- Fault-tolerance: Lambda architecture is designed to be fault-tolerant, with multiple layers and systems working together to ensure that data is processed and stored reliably.
- Flexibility: Lambda architecture is flexible and can handle a wide range of data processing workloads, from historical batch processing to streaming architecture.
While Lambda architecture offers a lot of advantages, it also has some significant drawbacks that businesses need to consider before deciding whether it is the right fit for their needs. Here are some disadvantages of using the Lambda architecture system:
- Complexity: Lambda architecture is a complex system that uses multiple layers and systems to process and store data. It can be challenging to set up and maintain, especially for businesses that are not familiar with distributed systems and data processing frameworks. Although its layers are designed for different pipelines, the underlining logic has duplicated parts causing unnecessary coding overhead for programmers.
- Errors and data discrepancies: With doubled implementations of different workflows (although following the same logic, implementation matters), you may run into a problem of different results from batch and stream processing engines. Hard to find, hard to debug.
- Architecture lock-in: It may be super hard to reorganize or migrate existing data stored in the Lambda architecture.
Use Cases for Lambda Architecture
Lambda architecture is a data processing architecture that is well-suited for a wide range of data processing workloads. It is particularly useful for handling large volumes of data and providing low-latency query results, making it well-suited for real-time analytics applications, such as dashboards and reporting. Lambda architecture is also useful for batch processing tasks, such as data cleansing, transformation, and aggregation, and stream processing tasks, such as event processing, machine learning models, anomaly detection, and fraud detection. In addition, Lambda architecture is often used to build data lakes, which are centralized repositories that store structured and unstructured data at rest, and is well-suited for handling the high-volume data streams generated by IoT devices.
Comparison of Lambda and Kappa Architectures
Both architectures are designed to provide scalable, fault-tolerant, and low latency systems for processing data, but they differ in terms of their underlying design and approach to data processing.
Data Processing Systems
Lambda architecture uses two separate data processing systems to handle different types of data processing workloads: a batch processing system and a stream processing system. In Kappa architecture, on the other hand, a single stream processing engine acts (stream layer) to handle complete data processing. In Lambda, programmers need to learn and maintain two processing frameworks and support any daily code changes in a doubled way. This separation (when not implemented in the same way) may cause different results in stream vs. batch processing, which may cause further business issues. Kappa Architecture uses the same code for processing data in real time, eliminating the need for additional effort to maintain separate codebases for batch and stream processing. This makes it a more efficient and error-proof solution.
Data Storage
Lambda architecture has a separate long-term data storage layer, which is used to store historical data and perform complex aggregations. Kappa architecture does not have a separate long-term data storage layer, and all data is processed and stored by the stream processing system.
Complexity
Lambda architecture is generally more complex to set up and maintain compared to Kappa architecture, as it requires two separate data processing systems and ongoing maintenance to ensure that the batch and stream processing systems are working correctly and efficiently. Kappa architecture is generally simpler, as it uses a single data processing system to handle all data processing workloads. On the other hand, Kappa, requires a mindset switch to think about all data as streams an it requires lots of experience in stream processing and distributed systems.

{kind=link}